分散とは
分散とは、平均値からのデータのバラつき、広がり具合を表す指標です。
例えば次の動画のように、データの分布が広がる(バラつきが大きくなる)に従って、分散の数値が大きくなります。
(平均について詳しく知りたい方は「平均値、中央値、最頻値」をご覧ください。)
分散の求め方
分散は、「各データと平均値の差の2乗」について平均を求めることによって計算されます。
平均が2回出てきてややこしいですね。
具体例で見てみましょう。
まずは与えられたデータから平均値を求めます。

次に各データについて、平均値との差の2乗を計算します。

最後に、上記について、平均を計算します。

以上のことを一般化した数式で表すと、分散を求める式は次になります。
\( \hspace{10pt} \displaystyle 分散 = s^{2} = \frac{\displaystyle \sum^{n}_{i=1}(x_{i}-\bar{x})^{2}}{n} \)
なお、分散を記号\( s^{2} \)で、\( n \)個のデータ\( x_{i} \)の平均値を\( \bar{x} \)で表しています。
「標準偏差とは」の所で分かりますが、分散は標準偏差(記号\( s\)で表します)の二乗ですので、\( s^{2} \)とします。
平均値を基準とした式になっていますので、分散が小さいとデータが平均値周辺に集まっていること、逆に大きいとデータが平均値から離れたところに分布していることになります。
Pythonを使用した分散の求め方
numpy
numpyライブラリを使用した標準偏差の計算は次の通りです。
import numpy as np
# 対象データ
data = np.array([136, 137, 139, 139, 140, 141])
# 分散を計算
variance = np.var(data)
# 出力
print("データの分散:", variance)
結果は以下となります。
データの分散: 2.8888888888888893pandas
pandasライブラリを使用した標準偏差の計算は次の通りです。
import pandas as pd
# 対象データ
data = [136, 137, 139, 139, 140, 141]
df = pd.Series(data)
# 分散を計算
sample_variance = df.var(ddof=0)
# 出力
print("データの分散:", sample_variance)
結果は以下となります。
データの分散: 2.8888888888888893標準偏差とは
標準偏差とは、分散の平方根をとることで元データと同じ単位にしたものです。
同じ単位にすることで感覚的に分かりやすい数値になります。
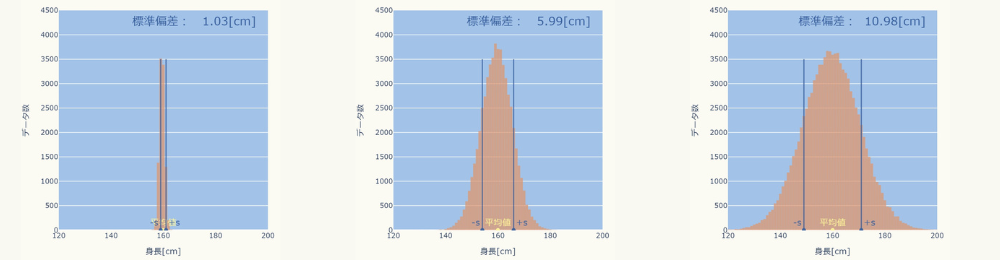
例えば、次の身長データの分布の動画のようになります。
標準偏差の単位は身長と同じ[cm]です。
なお、この身長データの分布は「分散とは」で見た動画と一緒です。
また、平均値±標準偏差の位置を+s、ーsで示しています。
分散と同じようにデータ分布が広がると標準偏差も大きくなります。
ただ、「分散とは」の動画では、分散が最終的に120.47という大きな数値になっていましたが、この動画では標準偏差は10.98です。
グラフ上にもプロットしていますが、分散と比べて感覚的にデータ分布の広がりが分かるような数値になっていると思います。
数式で表すと次になります。
\( \hspace{10pt} \displaystyle 標準偏差 = s = \sqrt{s^{2}} = \sqrt{\frac{\displaystyle \sum^{n}_{i=1}(x_{i}-\bar{x})^{2}}{n}} \)
標準偏差(standard deviation)の記号は\( s \)で表します。
具体例で見てみましょう。

Pythonを使用した標準偏差の求め方
numpy
numpyライブラリを使用した標準偏差の計算は次の通りです。
import numpy as np
# 対象データ
data = np.array([136, 137, 139, 139, 140, 141])
# 標準偏差を計算
std_deviation = np.std(data)
# 出力
print("データの標準偏差:", std_deviation)
結果は以下となります。
データの標準偏差: 1.699673171197595pandas
pandasライブラリを使用した標準偏差の計算は次の通りです。
import pandas as pd
# 対象データ
data = [136, 137, 139, 139, 140, 141]
df = pd.Series(data)
# 標準偏差を計算
sample_std_deviation = df.std(ddof=0)
# 出力
print("データの標準偏差:", sample_std_deviation)
結果は以下となります。
データの標準偏差: 1.699673171197595